Topic modeling is both an unsupervised machine learning and natural language processing technique capable of identifying topics out of a large corpus of documents. In other words it can create topic clusters from a large document collection. It can be used in many applications particularly in discourse analysis.
Latent Dirichlet Allocation (LDA) is one of the widely used algorithms in topic modeling. It is a bag of words method which considers words independently in the corpus. It doesn’t consider the order of the words. A topic consists of a distribution of words and a word can be in multiple topics.
One of the challenges in topic modeling is deciding the number of topics as we need to set the number of topics (k) in LDA in advance. There are two main approaches to this (1) get the k with the lowest perplexity (compute maximum log-likelihood) (2) qualitatively analyse multiple topics models with different k and decide what is the best depending on the context it is applied to.
Process of Generating Topic Models

In this section, I explain how to execute this process in R language for a collection of tweets.
First, we need to import required R packages.
library(NLP)
library (“tm”)
library(topicmodels)
Then, we need to follow the steps as shown in the above flow diagram.
Step 1: Load tweets from a csv file and fetch the CONTENT column
tweets <- read.csv(filePath, header = includesHeader) # load csv files
tweetContent <- iconv(tweets$CONTENT, to = “ASCII”, sub = “”) # fetch CONTENT column
Step 2: Pre-process/clean data
tweetTexts <- tolower(tweetTexts) #convert to lower cases
tweetTexts <- gsub(“rt”, ” “, tweetTexts) #remove the phrase “RT” from retweets
tweetTexts <- gsub(“@\w+”, ” “, tweetTexts) #remove usernames
urlPattern <- “http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+”
tweetTexts <- gsub(urlPattern, ” “, tweetTexts) #remove links
tweetTexts <- gsub(“[[:punct:]]”, ” “, tweetTexts) #remove punctuation
tweetTexts <- gsub(“[ |\t]{2,}”, ” “, tweetTexts) #remove tabs
tweetTexts <- gsub(“amp”, ” “, tweetTexts) # “&” is “&” in HTML
tweetTexts <- gsub(“^ “, “”, tweetTexts) #remove leading blanks
tweetTexts <- gsub(” $”, “”, tweetTexts) #remove trailing blanks
tweetTexts <- gsub(” +”, ” “, tweetTexts) #remove extra whitespaces
tweetTexts <- unique(tweetTexts) #remove duplicates (this may remove some of the retweets)!
tweetsCorpus <- Corpus(VectorSource(tweetTexts)) #convert to tm corpus
tweetsCorpus <- tm_map(tweetsCorpus, removeNumbers) #remove numbers
tweetsCorpus <- tm_map(tweetsCorpus,removeWords,stopwords(“en”)) #remove stop words (e.g. the, and etc.)
Step 3: Generate DTM (Document Term Matrix)
dtm <- DocumentTermMatrix(corpus)
Step 4: Run LDA
burnin <- 4000 #num of omitted iterations
iter <- 2000 #num of iterations made before the local optimum (default is 2000)
thin <- 500 #num of samples omitted in between iterations
seed <-list(2003,5,63,100001,765) # number of seeds should equal to nstart number
nstart <- 5 # num of repeated random starts
best <- TRUE
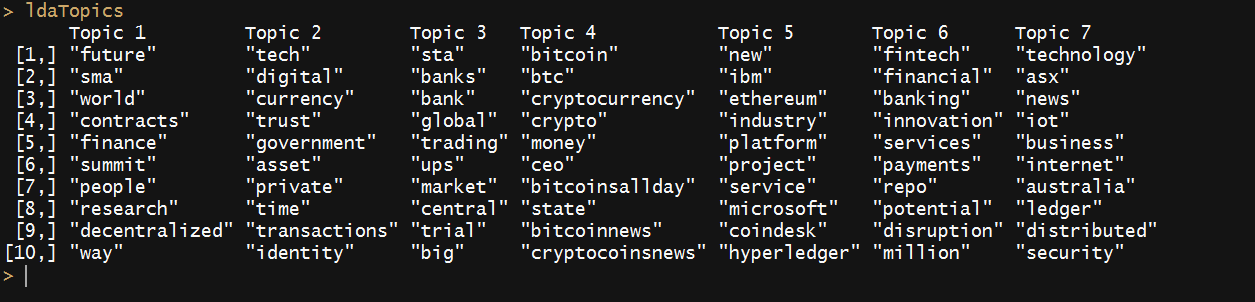
ldaOut <- LDA(dtm, 10 , method=”Gibbs”, control=list(nstart=nstart, seed = seed, best=best, burnin = burnin, iter = iter, thin=thin)) # use Gibbs sampling as estimation technique
topicList <- as.matrix(terms(ldaOut, 10))
This will result in 10 topics with 10 words per each topic.